

Generative AI: A Comprehensive Overview of Its History and Impact


Table of contents
- 1. What is Generative AI?
- 2. A Brief History of Generative AI
- 3. What are the Use Cases for Generative AI?
- 4. Generative AI Industry Impacts
- 5. Generative AI Models
- 6. How Does Generative AI Work?
- 7. Variational Autoencoders (VAEs)
- 8. Autoregressive Models
- 9. Attention Mechanism
- 10. GANs VS VAEs VS Autoregressive Models VS Transformer-based Models
- 11. The Future of Generative AI
Generative Adversarial Network (GAN), a type of machine learning algorithm, was introduced in 1962 in chatbots. By 2014, generative AI applications were able to create authentic images, videos, audio of real people, and synthetic data.
1. What is Generative AI?
Generative AI is a subset of artificial intelligence that focuses on creating new content, be it images, text, music, or even complex structures like 3D models. This is achieved by training a machine learning model on a dataset, where the model learns the underlying patterns or distributions. Once trained, these models can generate new instances that resemble the training data but are essentially new creations.
Two of the most popular generative models are Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). GANs work through a competitive process between two neural networks - a generator and a discriminator. The generator creates synthetic data instances, while the discriminator evaluates them for authenticity. VAEs, on the other hand, focus on producing a continuous, structured latent space, which is beneficial for certain applications.
For a deeper understanding, you can refer to the following resources:
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative Adversarial Networks. arXiv preprint arXiv:1406.2661. Link
Kingma, D. P., & Welling, M. (2013). Auto-Encoding Variational Bayes. arXiv preprint arXiv:1312.6114. Link
2. A Brief History of Generative AI
Generative AI has its roots in the early days of artificial intelligence, but it wasn't until the advent of deep learning that it truly began to flourish. In 2014, the concept of Generative Adversarial Networks (GANs) was introduced by Ian Goodfellow and his colleagues. This marked a significant milestone in the field of generative AI.
Subsequent years saw the development of more sophisticated models, such as the Deep Convolutional GAN (DCGAN), CycleGAN for unpaired image-to-image translation, and StyleGAN for high-fidelity natural image synthesis. Alongside GANs, Variational Autoencoders (VAEs) also gained popularity for their ability to create structured latent spaces.
For a detailed history, consider the following resources:
Goodfellow, I. (2016). NIPS 2016 Tutorial: Generative Adversarial Networks. arXiv preprint arXiv:1701.00160. Link
Radford, A., Metz, L., & Chintala, S. (2015). Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv preprint arXiv:1511.06434. Link

3. What are the Use Cases for Generative AI?
Generative AI has a wide range of applications. In the field of art and design, it is used to generate new images, music, and even design structures. Businesses use it to create realistic synthetic data for training other machine learning models. In healthcare, it's being used to create synthetic medical images for research and training.
In the domain of natural language processing, generative models are used to write text, translate languages, and even generate code. They also play a key role in creating realistic virtual environments, which are essential for video games and virtual reality experiences.
Here are some specific use cases for Generative AI:
Visual Applications:
Image Generation: Generative AI can be used to transform text into images and generate realistic images based on a setting, subject, style, or location. This can be useful in media, design, advertisement, marketing, education, and more.
Semantic Image-to-Photo Translation: Based on a semantic image or sketch, it's possible to produce a realistic version of an image. This application is particularly useful for the healthcare sector, assisting in diagnoses.
Image-to-Image Conversion: Generative AI can be used to transform the external elements of an image, such as its color, medium, or form while preserving its constitutive elements. This can be useful in various applications such as turning a daylight image into a nighttime image or manipulating the fundamental attributes of an image.
Image Resolution Increase (Super-Resolution): Generative AI can create a high-resolution version of an image through Super-Resolution GANs, useful for producing high-quality versions of archival material and/or medical materials that are uneconomical to save in high-resolution format. Another use case is for surveillance purposes.
Video Prediction: GAN-based video predictions can help detect anomalies that are needed in a wide range of sectors, such as security and surveillance.
3D Shape Generation: Generative AI is used to create high-quality 3D versions of objects. Detailed shapes can be generated and manipulated to create the desired shape.
Audio Applications:
Text-to-Speech Generator: Generative AI allows the production of realistic speech audio, removing the expense of voice artists and equipment. This is applicable in education, marketing, podcasting, advertisement, and more.
Speech-to-Speech Conversion: Generative AI can generate voiceovers for a documentary, a commercial, or a game without hiring a voice artist.
Music Generation: Generative AI can be used to generate novel musical materials for advertisements or other creative purposes.
Text-based Applications:
Text Generation: Generative AI can be used to create dialogues, headlines, or ads which are commonly used in marketing, gaming, and communication industries. They can be used in live chat boxes for real-time conversations with customers or to create product descriptions, articles, and social media content.
Personalized content creation: Generative AI can generate personalized content for individuals based on their personal preferences, interests, or memories. This could be in the form of text, images, music, or other media and could be used for social media posts, blog articles, or product recommendations.
Sentiment analysis/text classification: Generative AI can be used in sentiment analysis by generating synthetic text data that is labeled with various sentiments. This synthetic data can then be used to train deep learning models to perform sentiment analysis on real-world text data. It can also be used to generate text that is specifically designed to have a certain sentiment.
Generative AI has the potential to transform various sectors with its ability to create and innovate. While the possibilities are immense, it's crucial to consider ethical implications and potential misuse, particularly in the areas of deep fakes and the generation of misleading or false content. As the technology continues to evolve, it will be vital to develop robust guidelines and regulations to ensure its responsible use.
4. Generative AI Industry Impacts
Generative AI, which includes technologies such as Generative Adversarial Networks (GANs), is driving transformation across a wide range of industries. These AI algorithms can generate novel, realistic content such as images, music, and text, which has a multitude of applications and implications for various sectors. Here are some of the ways in which generative AI is impacting various industries:
Visual Applications
Image Generation
Generative AI can transform the text into images and generate realistic images based on specific settings, subjects, styles, or locations. This capability makes it possible to quickly and easily generate needed visual materials, which can be used for commercial purposes in media, design, advertising, marketing, education, and more. This is particularly useful for graphic designers who need to create a variety of images.
Semantic Image-to-Photo Translation
Generative AI can produce a realistic version of an image based on a semantic image or sketch. This application has potential uses in the healthcare sector, where it could aid in making diagnoses.
Image-to-Image Conversion
Generative AI can transform the external elements of an image, such as its color, medium, or form while preserving its constitutive elements. This can involve conversions such as turning a daylight image into a nighttime image or manipulating fundamental attributes of an image like a face. This technology can be used to colorize images or change their style.
Image Resolution Increase (Super-Resolution)
Generative AI can create high-resolution versions of images through Super-Resolution GANs. This is useful for producing high-quality versions of archival material and/or medical materials that are uneconomical to save in high-resolution format. It also has applications in surveillance.
Video Prediction
GAN-based video prediction systems comprehend both temporal and spatial elements of a video and generate the next sequence based on that knowledge. They can help detect anomalies, which is useful in sectors like security and surveillance.
3D Shape Generation
Though still a developing area, GAN-based shape generation can be used to create high-quality 3D versions of objects. This capability can be used to generate and manipulate detailed shapes.
Audio Applications
Text-to-Speech Generator
Generative AI can produce realistic speech audio. This technology has multiple business applications such as education, marketing, podcasting, advertising, etc. For example, an educator can convert their lecture notes into audio materials to make them more attractive. It can also be used to create educational materials for visually impaired people.
Speech-to-Speech Conversion
Generative AI can generate voices using existing voice sources. With speech-to-speech conversion, voiceovers can be created quickly and easily, which is advantageous for industries such as gaming and film.
Music Generation
Generative AI can be used in music production to generate novel musical materials for advertisements or other creative purposes. However, there are challenges to overcome, such as potential copyright infringement if copyrighted artwork is included in training data.
Text-based Applications
Text Generation
Generative AI is being trained to be useful in text generation. It can create dialogues, headlines, or ads, which are commonly used in marketing, gaming, and communication industries. These tools can be used in live chat boxes for real-time conversations with customers or to create product descriptions, articles, and social media content.
Personalized Content Creation
Generative AI can be used to generate personalized content for individuals based on their personal preferences, interests, or memories. This could be in the form of text, images, music, or other media and could be used for a variety of purposes such as:
Social media posts: Generative AI could generate personalized posts for individuals based on their past posts, interests, or activities.
Blog articles: AI could help generate articles tailored to an individual's interests, making the content more engaging.
Product recommendations: AI could generate personalized product recommendations based on an individual's past purchases or browsing history.
Personal content creation with generative AI has the potential to provide highly customized and relevant content, enhancing the user experience and increasing engagement.
Sentiment Analysis / Text Classification
Generative AI can be used in sentiment analysis by generating synthetic text data that is labeled with various sentiments (e.g., positive, negative, neutral). This synthetic data can then be used to train deep learning models to perform sentiment analysis on real-world text data. It can also be used to generate text that is specifically designed to have a certain sentiment, such as generating social media posts that are intentionally positive or negative in order to influence public opinion or shape the sentiment of a particular conversation.
In conclusion, generative AI is having a profound impact across many industries. Its ability to generate novel, realistic content can be used in numerous ways, from creating stunning visuals to producing personalized content. However, it also raises new challenges and ethical considerations, such as potential copyright infringement and the need for careful use of sentiment manipulation. As technology continues to evolve, we can expect to see even more innovative applications and a continued transformation of many industries.
5. Generative AI Models
Generative AI models are a subset of machine learning models that are designed to generate new data instances that resemble your training data. They can generate a variety of data types, such as images, text, and sound. Below are some of the most popular and influential generative models.
Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) are perhaps the most well-known generative models. Introduced by Goodfellow et al. in 2014, GANs consist of two neural networks: a generator network that produces synthetic data, and a discriminator network that tries to distinguish between real and synthetic data. The two networks are trained simultaneously in a game-theoretic framework, with the generator trying to fool the discriminator and the discriminator trying to correctly classify data as real or synthetic. GANs have been used to generate remarkably realistic images, among other things.
Variational Autoencoders (VAEs)
Variational Autoencoders (VAEs) are another type of generative model. They are based on autoencoders, which are neural networks that are trained to reconstruct their input data. However, unlike regular autoencoders, VAEs are designed to produce a structured latent space, which can be sampled to generate new data instances. VAEs also incorporate an element of stochasticity, which makes them a bit more flexible than regular autoencoders.
Autoregressive Models
Autoregressive models are a type of generative model that generates new data instances one component at a time. These models are based on the assumption that each component of your data depends only on the previous components. This makes them particularly well-suited to generating sequences, such as text or time-series data.
Transformer-based Models
Transformer-based models, such as GPT-3 and BERT, have recently become very popular for natural language processing tasks, including text generation. These models are based on the Transformer architecture, which uses a mechanism called attention to weigh the importance of different words in a sentence. Transformer-based models can generate remarkably coherent and contextually appropriate text.
References:
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., ... & Bengio, Y. (2014). Generative adversarial nets. In Advances in neural information processing systems (pp. 2672-2680).
Kingma, D. P., & Welling, M. (2013). Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language Models are Unsupervised Multitask Learners. OpenAI Blog, 1(8), 9.
6. How Does Generative AI Work?
Generative AI models, such as Generative Adversarial Networks (GANs), work by training two neural networks simultaneously: a generator and a discriminator.
Generator: This network takes a random noise vector as input and outputs an artificial data instance (e.g., an image). Its goal is to generate data that is as realistic as possible, such that the discriminator cannot distinguish it from real data.
Discriminator: This network takes a data instance as input (either a real one from the training set or an artificial one from the generator) and outputs a probability that the data instance is real. Its goal is to correctly classify real data as real and artificial data as artificial.
The two networks play a two-player minimax game, in which the generator tries to maximize the probability that the discriminator is fooled, and the discriminator tries to minimize this probability.
Mathematically, this can be represented by the following objective function, which the networks try to optimize:
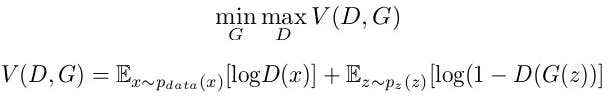
minG maxD: This notation refers to the two-player minimax game that the generator (G) and the discriminator (D) are playing. The generator is trying to minimize its objective function while the discriminator is trying to maximize its objective function.V (D, G): This is the value function that bothDandGare trying to optimize. It depends on both the current state of the discriminator and the generator.E: This symbol denotes the expectation, which can be roughly interpreted as the average value over all possible values of the random variable inside the brackets.x ~ pdata(x): This is a real data instancexdrawn from the true data distributionpdata(x).log D(x): This is the logarithm of the discriminator's estimate of the probability thatxis real. The discriminator wants to maximize this quantity, i.e., it wants to assign high probabilities to real data instances.z ~ pz(z): This is a noise vectorzdrawn from some prior noise distributionpz(z).G(z): This is the artificial data instance produced by the generator from the noise vectorz.log(1 - D(G(z))): This is the logarithm of one minus the discriminator's estimate of the probability that the artificial data instanceG(z)is real. The discriminator wants to maximize this quantity, i.e., it wants to assign low probabilities to artificial data instances. On the other hand, the generator wants to minimize this quantity, i.e., it wants the discriminator to assign high probabilities to its artificial data instances.
# Assume generator G and discriminator D are pre-defined neural networks
for epoch in range(num_epochs):
for real_data in data_loader:
# Train discriminator on real data
real_data_labels = torch.ones(real_data.size(0))
real_data_predictions = D(real_data)
d_loss_real = loss(real_data_predictions, real_data_labels)
# Train discriminator on fake data
noise = torch.randn(real_data.size(0), z_dim)
fake_data = G(noise)
fake_data_labels = torch.zeros(real_data.size(0))
fake_data_predictions = D(fake_data.detach())
d_loss_fake = loss(fake_data_predictions, fake_data_labels)
# Update discriminator
d_loss = d_loss_real + d_loss_fake
d_optimizer.zero_grad()
d_loss.backward()
d_optimizer.step()
# Train generator
fake_data_predictions = D(fake_data)
g_loss = loss(fake_data_predictions, real_data_labels)
# Update generator
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
7. Variational Autoencoders (VAEs)
Variational Autoencoders (VAEs) are a type of generative model that allows for the generation of new data points that resemble the input data. They do this by learning a compressed, or latent, representation of the input data.
Introduction to VAEs
VAEs belong to the family of generative models and are primarily used to learn complex data distributions. They are based on neural networks and use techniques from probability theory and statistics.
Architecture of VAEs
VAEs have a unique architecture consisting of two main parts: an encoder and a decoder. The encoder takes in input data and generates a compressed representation, while the decoder takes this representation and reconstructs the original input data.
Encoder
The encoder in a VAE takes the input data and transforms it into two parameters in a latent space: a mean and a variance. These parameters are used to sample a latent representation of the data.
Decoder
The decoder in a VAE takes the latent representation and uses it to reconstruct the original data. The quality of the reconstruction is measured using a loss function, which guides the training of the VAE.
Training VAEs
Training a VAE involves optimizing the parameters of the encoder and decoder to minimize the reconstruction loss and a term called the KL-divergence, which ensures that the learned distribution stays close to a pre-defined prior distribution, usually a standard normal distribution.
Applications of VAEs
VAEs have a wide range of applications, from image generation to anomaly detection. They are particularly useful in scenarios where we need to generate new data that is similar to, but distinct from, the training data.
Mathematics of VAEs
The goal of a VAE is to learn a probabilistic mapping of input data x into a latent space z, and then back again. The VAE architecture comprises two parts: the encoder q(z|x) and the decoder p(x|z).
The encoder models the probability distribution q(z|x) which represents the distribution of latent variables given the input. It outputs two parameters: a mean μ and a standard deviation σ which together define a Gaussian distribution. We can sample z from this Gaussian distribution.
The decoder models the probability distribution p(x|z) which represents the distribution of data given the latent representation. It takes a point z in the latent space and outputs parameters of a distribution over the data space.
The VAE is trained by maximizing the Evidence Lower BOund (ELBO) on the marginal likelihood of x:
ELBO = E[log p(x|z)] - KL(q(z|x) || p(z))
The first term is the reconstruction loss and the second term is the KL-divergence between the approximate latent distribution q(z|x) and the prior p(z).
import torch
from torch import nn
class VAE(nn.Module):
def __init__(self, input_dim, latent_dim):
super(VAE, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(input_dim, 128),
nn.ReLU(),
nn.Linear(128, latent_dim * 2) # We need two parameters (μ and σ) for each dimension in the latent space
)
self.decoder = nn.Sequential(
nn.Linear(latent_dim, 128),
nn.ReLU(),
nn.Linear(128, input_dim),
nn.Sigmoid() # To ensure the output is a probability distribution
)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5*logvar)
eps = torch.randn_like(std)
return mu + eps*std
def forward(self, x):
h = self.encoder(x)
mu, logvar = torch.chunk(h, 2, dim=-1) # Split the encoder output into two equal parts
z = self.reparameterize(mu, logvar)
return self.decoder(z), mu, logvar
def loss_function(recon_x, x, mu, logvar):
BCE = nn.functional.binary_cross_entropy(recon_x, x, reduction='sum')
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE + KLD
In the forward function, the input x is passed through the encoder which outputs the parameters mu and logvar of the latent distribution q(z|x). A latent variable z is then sampled from this distribution using the reparameterize function. This z is passed through the decoder to obtain a reconstruction of the input x.
The loss function in a variational autoencoder (VAE) computes the Evidence Lower Bound (ELBO), which consists of two terms: the reconstruction term and the regularization term.
The reconstruction term is the binary cross-entropy loss between the original input x and the reconstructed output. This is computed by taking the negative log-likelihood of the Bernoulli distribution, which models each pixel in the image. The goal of this term is to minimize the reconstruction error, essentially making the output as close as possible to the original input.
The regularization term is the Kullback-Leibler (KL) divergence between the encoded distribution and standard normal distribution. This term serves to regularize the organization of the latent space by making the distributions returned by the encoder close to a standard normal distribution. The KL divergence between two Gaussian distributions can be expressed directly in terms of the means and covariance matrices of the two distributions. The KL divergence term acts as a kind of penalty, discouraging the model from encoding data too far apart in the latent space and encouraging overlap of the encoded distributions. This helps to satisfy the continuity and completeness conditions required for the latent space.
The encoding and decoding process in a VAE is carried out by two networks: the encoder and the decoder. The encoder network takes an input observation and outputs a set of parameters (mean and log-variance) for specifying the conditional distribution of the latent representation z. The decoder network takes a latent sample z as input and outputs the parameters for a conditional distribution of the observation. To generate a sample z for the decoder during training, you can sample from the latent distribution defined by the parameters outputted by the encoder, given an input observation x. However, this sampling operation creates a bottleneck because backpropagation cannot flow through a random node. To address this, the reparameterization trick is used, which allows backpropagation to pass through the parameters of the distribution, rather than the distribution itself.
In the training process, the model begins by iterating over the dataset, computing the mean and log-variance of the Gaussian distribution in the encoder's last layer, and sampling a point from this distribution using the reparameterization trick. This point is then decoded in the decoder, and the loss is computed as the sum of the reconstruction error and the KL divergence, which is then minimized during training.
References
Kingma, D. P., & Welling, M. (2013). Auto-Encoding Variational Bayes. arXiv preprint arXiv:1312.6114.
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
Doersch, C. (2016). Tutorial on Variational Autoencoders. arXiv preprint arXiv:1606.05908.
Lilian, W., & Ghahramani, Z. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540), 529-533.
8. Autoregressive Models
Autoregressive models are commonly used for modeling temporal data, such as time series. These models leverage the concept of "autoregression", meaning that they predict future data points based on the previous ones. This is done by assuming that the current output is a linear combination of the previous outputs plus some error term.
Mathematical Operations
The mathematical representation of an autoregressive model of order p, denoted as AR(p), is given by:
X_t = c + Σ (φ_i * X_(t-i)) + ε_t
Where:
X_t is the output at the time
t.c is a constant.
φ_i are the parameters of the model.
X_(t-i) is the output at the time
t-i.ε_t is a random error term.
The coefficients φ1, φ2,...,φp are the parameters of the model that are estimated from the data, and ε_t is a random error term.
Code
from statsmodels.tsa.ar_model import AutoReg
import numpy as np
# Generate some data
np.random.seed(1)
n_samples = int(1000)
a = 0.6
x = np.random.normal(size=n_samples)
y = np.zeros_like(x)
y[1] = x[1] + a*x[0]
for t in range(2, n_samples):
y[t] = x[t] + a*x[t-1]
# Fit an AR(p) model
model = AutoReg(y, lags=1)
model_fit = model.fit()
# Make predictions
yhat = model_fit.predict(len(y), len(y))
print(yhat)
References
9. Attention Mechanism
The attention mechanism is a key innovation in the field of artificial intelligence, particularly in the area of natural language processing and machine translation. It allows models to focus on relevant parts of the input sequence when generating output, thus improving the quality of the predictions.
What is Attention Mechanism?
The attention mechanism is a concept that was introduced to improve the performance of neural network models on tasks such as machine translation, text summarization, and image captioning. It addresses the limitation of encoding the input sequence into a fixed-length vector from which the decoder generates the output sequence. With the attention mechanism, the decoder can "look back" into the input sequence and "focus" on the information that it needs.
How Does Attention Mechanism Work?
The attention mechanism works by assigning a weight to each input in the sequence. These weights determine the amount of 'attention' each input should be given by the model when generating the output. Higher weights indicate that the input is more relevant or important to the current output being generated.
The weights are calculated using an attention score function, which takes into account the current state of the decoder and the input sequence. The attention scores are then passed through a softmax function to ensure they sum up to one, creating a distribution over the inputs.
Once the weights are calculated, they are multiplied with their corresponding inputs to produce a context vector. This context vector is a weighted sum of the inputs, giving more importance to the inputs with higher attention weights. The context vector is then fed into the decoder to generate the output.
Types of Attention Mechanisms
There are several types of attention mechanisms, including:
1. Soft Attention: Soft attention computes a weighted sum of all input features. The weights are calculated using a softmax function, which allows the model to distribute its attention over all inputs but with different intensities.
2. Hard Attention: Hard attention, on the other hand, selects a single input to pay attention to and ignores the others. It is a discrete operation and thus harder to optimize compared to soft attention.
3. Self-Attention: Self-attention, also known as intra-attention, allows the model to look at other parts of the input sequence to get a better understanding of the current part it is processing.
Attention Mechanism in Transformer Models
The Transformer model, used in models like BERT, GPT-2, and T5, relies heavily on the attention mechanism, specifically self-attention. It allows the model to consider the entire input sequence at once and weigh the importance of different parts of the sequence when generating each word in the output. This results in models that are better at understanding context and handling long-range dependencies in the data.
Mathematical Operations
Let's assume we have an input sequence X = {x1, x2, ..., xT} and the hidden states H = {h1, h2, ..., hT} generated by an encoder (like an RNN). The goal of the attention mechanism is to generate a context vector that's a weighted sum of these hidden states. The weights represent the importance of each hidden state in generating the output.
The steps involved in the attention mechanism are:
Score Calculation: This is the first step where we calculate the attention scores for each hidden state. The scores are calculated based on the similarity between the hidden state and the current state of the decoder. There are several ways to calculate this score. For instance, if we use a simple dot product to measure the similarity, the score for each hidden state
htis calculated asscore(ht) = ht . st, wherestis the current state of the decoder.Softmax Layer: The scores are then passed through a softmax function to convert them into attention weights. The softmax function ensures that all the weights sum up to 1. The weight for each hidden state
htis calculated asweight(ht) = exp(score(ht)) / Σ exp(score(hi))for alli.Context Vector Calculation: The final step is to calculate the context vector, which is a weighted sum of the hidden states. The context vector
Cis calculated asC = Σ weight(ht) * htfor allt.
Python Code Example
import torch
import torch.nn.functional as F
import math
def attention(query, key, value):
# Query, Key, Value are the hidden states in the shape (batch_size, sequence_length, hidden_dim)
# Step 1: Score Calculation
# We're using scaled dot product for score calculation
scores = torch.bmm(query, key.transpose(1, 2)) / math.sqrt(query.size(-1))
# Step 2: Softmax Layer to get the weights
weights = F.softmax(scores, dim=-1)
# Step 3: Calculate the context vector
context = torch.bmm(weights, value)
return context, weights
# Assume we have hidden states from an encoder
hidden_states = torch.rand((64, 10, 512)) # batch_size=64, sequence_length=10, hidden_dim=512
# For simplicity, we'll use the same hidden states as query, key, value
query, key, value = hidden_states, hidden_states, hidden_states
context, weights = attention(query, key, value)
References:
Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).
Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhudinov, R., ... & Bengio, Y. (2015). Show, attend, and tell: Neural image caption generation with visual attention. In International conference on machine learning (pp. 2048-2057). PMLR.
10. GANs VS VAEs VS Autoregressive Models VS Transformer-based Models
Generative models are a cornerstone of artificial intelligence, used in a variety of applications. Here, we compare four main types: Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), Autoregressive Models, and Transformer-based Models.
Generative Adversarial Networks (GANs)
GANs, introduced by Goodfellow et al., are composed of two neural networks: the generator and the discriminator. The generator creates new data instances, while the discriminator evaluates them for authenticity; i.e., it decides whether each instance of data that it reviews belong to the actual training dataset or not.
Pros:
GANs can generate very high-quality and realistic images.
GANs learn to capture and replicate the distribution of the training data.
Cons:
They can be difficult to train due to instability, leading to non-converging loss of functions.
They often require a large amount of data and computing resources.
Variational Autoencoders (VAEs)
VAEs, proposed by Kingma and Welling, are generative models that use the principles of deep learning to serve both as a generator and as a representation learning method. They attempt to model the observed variables as a function of certain latent variables which are not observed.
Pros:
VAEs provide a framework for seamlessly blending unsupervised and supervised learning.
VAEs are more stable to train than GANs.
Cons:
The images generated by VAEs are often blurrier compared to GANs.
It can be challenging to interpret the learned latent space.
Autoregressive Models
Autoregressive models generate sequences based on previous data. They predict the output at a given time, conditioned on the outcomes at previous time steps.
Pros:
They are particularly well-suited for time-series data.
They can capture complex temporal dependencies.
Cons:
They can be slow to generate new instances, as they have to proceed sequentially.
They may struggle with long-term dependencies due to the "vanishing gradients" problem.
Transformer-based Models
Transformer-based models, such as GPT and BERT, use the Transformer architecture to generate text. These models have achieved state-of-the-art performance on a variety of natural language processing tasks.
Pros:
They can generate remarkably coherent and contextually appropriate text.
They are able to capture long-term dependencies in the data.
Cons:
Transformer-based models require large amounts of data and computational resources to train.
They can generate text that is coherent on a local scale but lacks global coherence or a consistent narrative.
References:
Goodfellow, I., et al. (2014). Generative adversarial nets. In Advances in neural information processing systems (pp. 2672-2680).
Kingma, D. P., & Welling, M. (2013). Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114.
Vaswani, A., et al. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).
Radford, A., et al. (2019). Language Models are Unsupervised Multitask Learners. OpenAI Blog, 1(8), 9.
11. The Future of Generative AI
Generative AI is a rapidly evolving field with vast potential for diverse applications. As we continue to improve our understanding and refine these models, we can expect to see significant advancements in numerous areas. These areas include but are not limited to, art, music, language, and more.
As with any technology, predicting the future of generative AI involves a certain degree of speculation. However, given current trends, we can anticipate some potential developments:
Better Quality Generations: As generative AI models become more sophisticated, the quality of their outputs is likely to improve.
Greater Accessibility: As these technologies become more widespread and user-friendly, more people will be able to use and benefit from them.
Ethical and Policy Discussions: As generative AI becomes more prevalent, society will need to engage in discussions about the ethical implications and policy requirements of these technologies.